
Les 10 erreurs vibe coding qui coûtent vraiment cher en 2026 ne sont pas techniques. Elles sont décisionnelles. Tu peux écrire un mauvais prompt, l'IA finit par corriger. Tu peux empiler des hallucinations, l'éditeur finit par te le signaler. Mais une clé API en clair pushée sur GitHub, un projet de 12 000 lignes jamais relu, une dépendance totale à Lovable le jour où Lovable change ses tarifs : ça ne se rattrape pas en un prompt. Cet article classe les 10 pièges par gravité × probabilité, donne les 4 obligatoires sécurité avant production, et te donne la checklist de récupération si ton projet a déjà dérivé. Le vibe coding marche, pour les gens qui acceptent qu'écrire le prompt n'est qu'1 % du job. Le reste, c'est lire, valider, refactor, sécuriser. Si tu débarques sans contexte, va d'abord lire la définition canonique du vibe coding.
La matrice "gravité × probabilité" des erreurs vibe coding

L'erreur la plus visible n'est pas la plus fréquente. La plus fréquente n'est pas la plus grave. C'est la combinaison qui te ruine. La liste qui suit est triée par produit gravité × probabilité, pas par "ce qui fait peur dans les blogs sécu".
Les 10 erreurs, classées par gravité décroissante
1. Mettre une clé API en clair dans le code généré
C'est l'erreur n°1, celle dont tu te diras "ça n'arrivera pas chez moi". Elle arrive. Quand tu demandes à l'IA d'intégrer OpenAI, Stripe, Resend, elle colle la clé dans le fichier, pas dans un .env. Et ton commit push tout sur GitHub.
GitHub scanne, les bots aussi. Si ta clé OpenAI traîne 20 minutes en repo public, elle est revendue le soir même. Réflexe : .env.local git-ignored et gitleaks en pre-commit hook.
2. Ne jamais relire ce que l'IA a écrit
Tu prompt, ça marche, tu passes au feature suivant. Trois semaines plus tard, 8 000 lignes que personne n'a lues. Quand une feature casse, tu n'as aucune idée de pourquoi. L'IA non plus, elle a perdu le contexte entre deux sessions.
Règle d'audit : si ton projet dépasse 1 000 lignes générées sans relecture, c'est déjà trop tard pour ne rien faire. Pose-toi 2 heures, relis section par section, supprime ce que tu ne comprends pas, demande à l'IA d'expliquer ce qui reste.
3. Empiler les prompts au lieu de refactor
Une feature ne marche pas. Tu prompt un fix. Le fix casse autre chose. 30 prompts plus tard, ton code est un sandwich où chaque couche annule la précédente. L'IA n'a aucune mémoire de ce que tu as empilé.
Refactor n'est pas un mot tabou. Toutes les 10 features ajoutées : demande à l'IA de réécrire la section en partant de zéro, avec le seul comportement attendu. Tu jettes 60 % du code généré. C'est le but.
4. Dépendre d'un seul éditeur (Lovable-only ou Bolt-only)
Tu as tout vibecodé sur Lovable. Demain, Lovable triple ses tarifs ou ferme. Tu n'as pas le code, pas le hosting, juste un compte. Game over.
Lovable et Bolt offrent l'export. Tu l'exportes dès semaine 2, pushes sur ton GitHub, ajoutes Vercel ou Netlify comme deploy alternatif. Ton stack reste portable, c'est la vraie ligne de défense.
5. Skipper l'auth et la sécurité minimale parce que "c'est pas en prod"
"Je gère plus tard". Personne ne gère plus tard. Le jour où tu envoies le lien à 5 testeurs, ton MVP est en prod. Sans Supabase Auth ou Clerk dès semaine 1, tu auras 3 utilisateurs avec des permissions admin "par défaut" que tu ne sauras pas révoquer. Les quatre obligatoires (détaillés plus bas) : secrets en variables d'env, validation des inputs, auth + permissions, logs basiques.
6. Ignorer la dette quand le projet dépasse 1 000 lignes
À 300 lignes, l'IA garde le contexte. À 1 500 lignes, elle hallucine sur le fichier 4. À 5 000, c'est une loterie. Passé un seuil, chaque feature coûte le double de la précédente.
Seuil de bascule observé sur les projets founders 2025-2026 : 1 000 à 1 500 lignes. À ce stade, découpe en modules, écris un README contextuel pour l'IA, et bascule sur Cursor ou Claude Code (qui voient toute la codebase) plutôt qu'un éditeur cloud limité à un fichier à la fois.
7. Confondre prototype et "release-ready"
Ton MVP marche sur ton Mac. Tu l'envoies à un VC en demo. Ça crashe. Pas parce que ton code est nul, mais parce que tu as oublié 12 cas limites : formulaire vide, timeout réseau, refresh à mi-flow, paiement décliné, double-clic sur submit.
Un prototype : ça marche dans le happy path. Release-ready : ça ne crashe pas sur les 20 chemins moins glamour. La différence représente 30 à 40 % du temps total.
8. Sous-estimer le temps de finition (la dernière phase est la plus longue)
Tu as shipé la v1 en 5 jours. Tu te dis "encore 2 jours et c'est propre". Trois semaines plus tard, tu y es encore. La finition (polish UI, edge cases, mobile responsive, micro-bugs, copy, performance) prend systématiquement plus de temps que le happy path.
Loi empirique : 70 % du travail visible se fait en 30 % du temps. Les 30 % restants vont prendre 70 %. Budget en conséquence.
9. Scope creep silencieux (l'IA accepte tout)
L'IA ne dit jamais "mauvaise idée". Dashboard analytics au milieu de l'onboarding ? Elle l'ajoute. Mode dark la veille du launch ? Elle le fait. Trois jours plus tard, un Frankenstein avec 4 features démarrées, zéro finie.
Discipline : note chaque feature ajoutée au scope, une à la fois, termine avant la suivante. L'IA est un yes-man sans coût marginal apparent. Le coût s'appelle "ton projet ne sort jamais".
10. Ne pas avoir de plan B si l'outil change ses tarifs ou ferme
Les éditeurs lèvent à des valorisations à 10 chiffres en 2026. Ils changeront leur tarification, certains fermeront. Plan B dès semaine 1 : code exporté, hébergement séparé, paiements et auth gérés par des services tiers (Stripe, Supabase, Clerk) indépendants de l'éditeur. Si tout est ficelé à Lovable ou Bolt, ton produit n'est pas le tien.
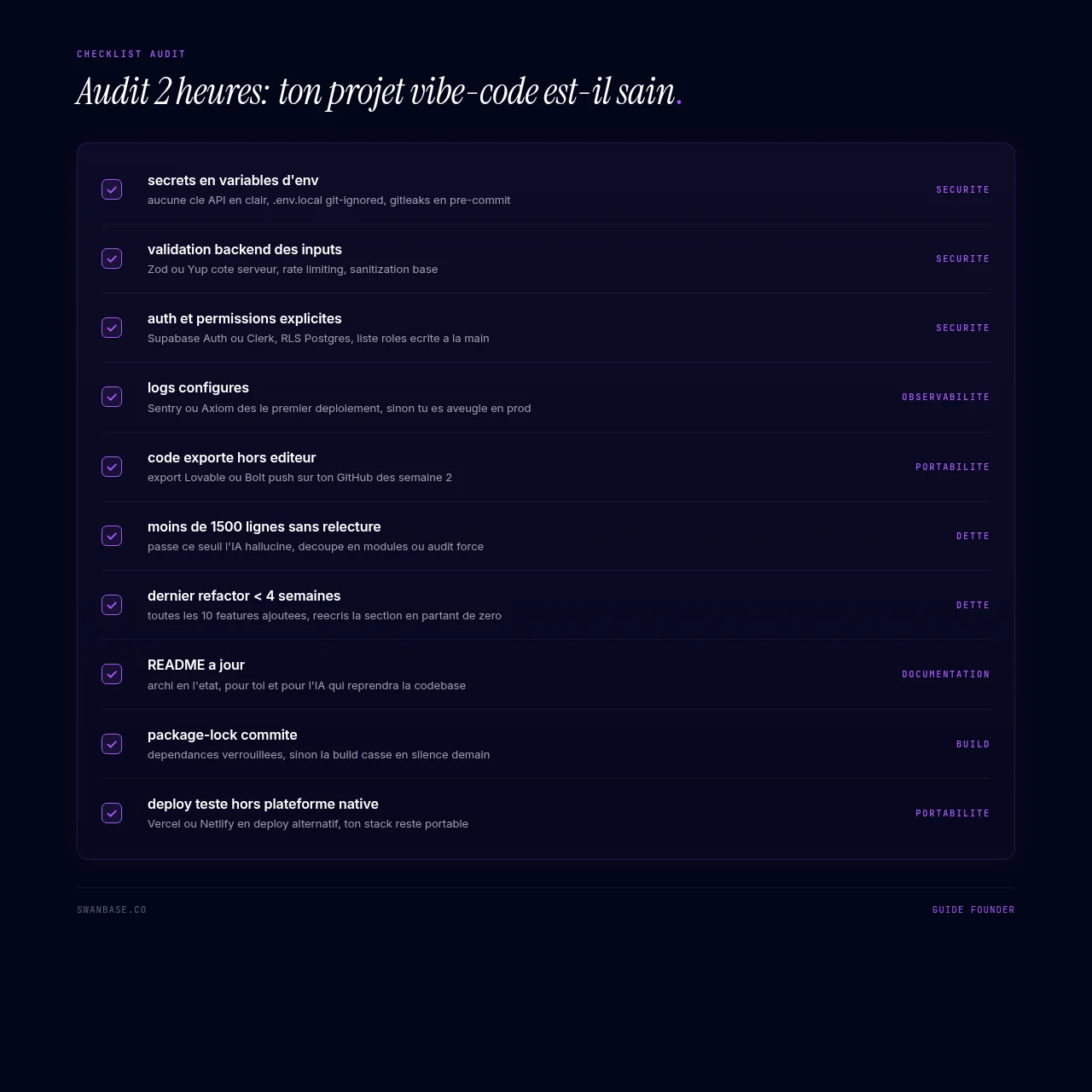
Sécurité : les 4 obligatoires avant production
Le SERP est saturé d'articles "Les failles du vibe coding". Le résumé tient en 4 lignes.
Secrets et clés API
Aucune clé en clair dans le code. Jamais. .env.local, .gitignore, secrets manager du hosting (Vercel, Railway, Render exposent ça en 2 clics). gitleaks en pre-commit, secret scanning GitHub activé.
Validation des inputs
Tout input utilisateur est hostile par défaut. L'IA valide souvent uniquement côté front. Ajoute : validation backend (Zod, Yup), rate limiting (Upstash, Vercel WAF), sanitization des inputs qui touchent à la base.
Auth et permissions
Données utilisateur = Row Level Security (Supabase, Postgres natif) ou middleware d'auth obligatoire. L'IA ne le code pas par défaut. Liste des permissions par rôle écrite à la main, pas générée à la louche.
Logs et monitoring basique
Sentry ou Axiom dès le premier déploiement. Un projet vibe-codé sans logs est aveugle : quand une feature casse en prod, tu n'as que le mail d'un user énervé pour le savoir.
Hallucinations : comment les détecter et les corriger
Patterns visuels d'hallucination
Quatre signaux te disent que l'IA invente. Un : un import de package qui n'existe pas (vérifie sur npm ou PyPI). Deux : une fonction appelée sur un objet qui ne l'expose pas (genre .toDateString() sur une string). Trois : des paramètres d'API qui ne sont pas dans la doc officielle (l'IA invente des champs Stripe régulièrement). Quatre : du code qui "marche" mais ne fait rien de ce que tu as demandé, la fonction est écrite, jamais appelée.
3 réflexes à avoir
Quand un truc casse, ne re-prompt pas tout de suite. Lis l'erreur, cherche la fonction ou le package sur la doc officielle. Si tu n'as pas le temps, demande explicitement : "vérifie que ce code utilise des fonctions qui existent vraiment dans la doc de [X], cite la source". L'IA reconnaît son hallucination la moitié du temps.
Tu es déjà dans le mur ? La checklist de récupération
C'est la section que les autres guides ne te donnent pas. Ils te disent comment éviter. Personne ne te dit quoi faire après.

Audit rapide (2 heures)
Session de 2 heures. Liste : nombre de fichiers, nombre de lignes, secrets qui traînent, dépendances non verrouillées, dernière feature qui marchait vraiment. Écris ce diagnostic dans AUDIT.md. C'est ta photo de référence avant intervention.
Refonte progressive vs refonte from scratch
Moins de 2 000 lignes et un bug bloquant : refonte from scratch plus rapide. Reprends le brief initial, génère une v2 propre, migre les données. Une semaine au lieu de deux mois.
Plus de 5 000 lignes ou des utilisateurs actifs : refonte progressive. Identifie le module le plus pourri (souvent l'auth ou le checkout), réécris-le isolé, bascule quand c'est testé. Pas de big bang.
Quand appeler un dev "humain" pour auditer
Trois signaux. Un : tu touches à des données sensibles (paiement, santé, pro) et tu ne sais pas dire ce que ton code en fait. Deux : ton projet dépasse 5 000 lignes et ton coût en prompts dépasse le coût horaire d'un freelance. Trois : tu vas faire payer le produit en moins de 4 semaines. Le freelance n'a pas besoin de refaire ton code, juste de 4 heures pour te dire ce qui craint.
Migration d'outil sans tout casser
Plan B activé : export du code en local, push sur ton repo perso, session Cursor ou Claude Code sur la codebase locale, demande à l'IA un README qui décrit l'archi en l'état, puis reprends depuis cette base. 1 à 3 jours selon la taille.
Quand le vibe coding n'est pas la bonne réponse
Produits temps-réel critiques
Trading algorithmique, télémédecine en visio, jeu multijoueur synchrone, contrôle industriel. Une latence de 200 ms est interdite. Le code généré par IA, même excellent, a souvent des inefficacités cachées : boucles redondantes, requêtes N+1, appels séquentiels là où la concurrence s'imposait. Il te faut un dev qui profile et optimise.
Conformité réglementaire stricte (RGPD, finance, santé)
PCI-DSS (paiements), HDS (santé), data RGPD sensible, AMF (finance) : tu dois produire des audits, des logs traçables, une chaîne de responsabilité documentée. Le vibe coding ne génère pas ces artefacts par défaut. Un dev les produit naturellement.
Scale au-delà de 10 000 utilisateurs actifs
Aucun éditeur vibe coding n'optimise pour la performance à scale. 1 000 users sans douleur, 5 000 si l'archi est propre, au-delà tu refactor sérieusement avec un dev. Ce n'est pas un défaut, c'est le contrat : l'outil optimise pour la vitesse de mise en marché, pas pour le coût d'opération à scale.
Hors de ces trois cas, le vibe coding reste la voie la plus rapide pour valider ton idée. Va relire la définition complète du vibe coding pour cadrer où il sert.
FAQ
Combien de temps avant qu'un projet vibe-codé devienne ingérable ?
Empiriquement, 6 à 12 semaines sans refactor, ou 1 500 à 2 000 lignes générées sans relecture. Au-delà, chaque feature coûte le double de la précédente. Bon réflexe : un audit toutes les 4 semaines ou 800 lignes ajoutées, avec refactor partiel à chaque audit.
Faut-il forcément faire auditer son code par un dev humain ?
Pas toujours. Nécessaire si tu manipules des données sensibles, vises plus de 5 000 utilisateurs payants, ou si ton produit fait partie d'une chaîne de responsabilité légale. Pour un MVP qui teste une idée auprès de 200 users, une relecture sérieuse par toi-même suffit, accompagnée d'une revue par l'IA elle-même.
Le vibe coding est-il dangereux pour un MVP présenté à un VC ?
Non, si le MVP fait sa démo sans crasher. Un VC pre-seed regarde la traction et l'équipe, pas la pureté du code. Plusieurs founders en 2026 ont levé avec des MVP vibe-codés. Le piège : prétendre que c'est du "vrai code de prod" quand ça ne l'est pas. Sois honnête, le VC s'en fiche.
Mon projet plante après 2 mois, tout est à refaire ?
Très rarement. La plupart du temps, le projet plante à cause d'1 ou 2 modules pourris : souvent l'auth, le state management ou l'intégration paiement. Audit en 2 heures, réécriture de ce seul module depuis le brief original. 3 à 7 jours selon la complexité. Le reste est sauvable.







